Computes the height-height correlation function for an AFM data object; note
that any background should be removed first. Since the full computation would
be lengthy, yet a random subset generally converges to the full result, the
numIterations parameter is used to limit the iterations. It should be
increased for images with more pixel resolution. With higher resolution, the
degRes should also be increased. For each iteration a random pixel
and a random angle with resolution degRes is generated Then, the height-height
correlation \(g(r) = |h(x) - h(x+r)|^2\) for that point is computed,
where \(r\) stretches from 1 to pixel resolution of the image (scaled by
r.percentage). Since the AFM image is generally square, some locations / angles
will not have data for large r and are ignored. Given the random numbers, slightly
different results may be obtained in different runs. To limit the variation, the
same random numbers can be used, when the randomSeed is populated with a
prime number. It is recommended to run with allResults = TRUE.
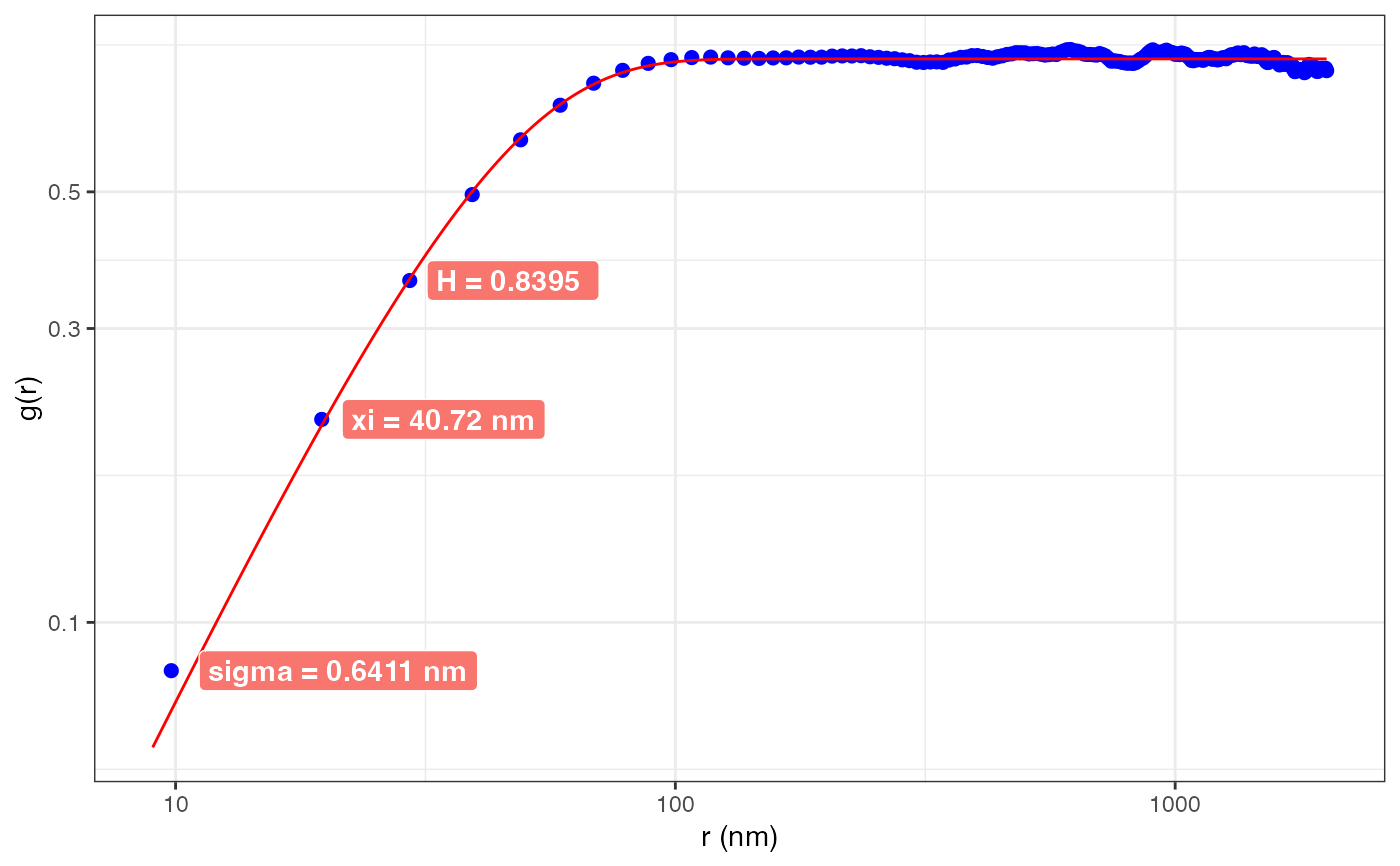
The resulting data curve \(g(r)\) is fit to the following equation: \(2 \sigma^2 (1 - \exp \left[ -(\frac{r}{\xi})^{2H} \right] ) \)
\(\sigma\): roughness
\(\xi\): correlation length
\(H\): Hurst parameter, \(\alpha=2H\)
Publication: http://iopscience.iop.org/article/10.1088/1742-6596/417/1/012069 Title: Height-Height Correlation Function to Determine Grain Size in Iron Phthalocyanine Thin Films Authors: Thomas Gredig, Evan A. Silverstein, Matthew P Byrne Journal: J of Phys: Conf. Ser. Vol 417, p. 012069 (2013).
AFM.hhcf(
obj,
no = 1,
numIterations = 10000,
addFit = TRUE,
dataOnly = FALSE,
degRes = 100,
r.percentage = 80,
xi.percentage = 70,
randomSeed = NA,
allResults = FALSE,
verbose = FALSE
)Arguments
- obj
AFMdata object
- no
channel number
- numIterations
Number of iterations (must be > 1000), but 10^6 recommended
- addFit
if
TRUEa fit is added to the data- dataOnly
if
TRUEreturns data frame, otherwise returns a graph (OBSOLETE, use allResults)- degRes
resolution of angle, the higher the better, should be >100, 1000 is also good, but takes more time
- r.percentage
a number from 10 to 100 representing the distance to compute, since the image is square, there are not as many points that are separated by the full length, 80 is a good value, if there is no fit, the value can be reduced to 70 or 60.
- xi.percentage
a number from 10 to 100 representing where correlation length could be found from maximum (used for fitting)
- randomSeed
(optional) a large number, if set, the random numbers are seeded and the results are reproducible
- allResults
if
TRUEreturns graph, data and fit parameters as list- verbose
output time if
TRUE
Value
graph, data frame with g(r) and $num indicating number of computations used for r, or a list with the graph, data.frame, fit parameters
Examples
filename = AFM.getSampleImages(type='tiff')
a = AFM.import(filename)
a = AFM.flatten(a)
r = AFM.hhcf(a, numIterations = 1e5, allResults = TRUE)
head(r$data) # output HHCF data
#> r.nm g num
#> 1 9.803922 0.08348331 99735
#> 2 19.607843 0.21356454 99267
#> 3 29.411765 0.35890053 98788
#> 4 39.215686 0.49488124 98300
#> 5 49.019608 0.60735017 97848
#> 6 58.823529 0.69120600 97359
head(r$fitData) # fit data curve data
#> r.nm g
#> 1 9 0.06267795
#> 2 10 0.07424288
#> 3 11 0.08642609
#> 4 12 0.09916788
#> 5 13 0.11241165
#> 6 14 0.12610347
head(r$fitParams) # output fit parameters
#> sigma xi Hurst sigma.err xi.err Hurst.err
#> 1 0.6410569 40.71622 0.8394778 0.000467331 0.6549884 0.03279422
r$graph # output ggplot2 graph