Estimate Peak Position
estimatePeak.RmdFind the largest peak in a sub dataset.
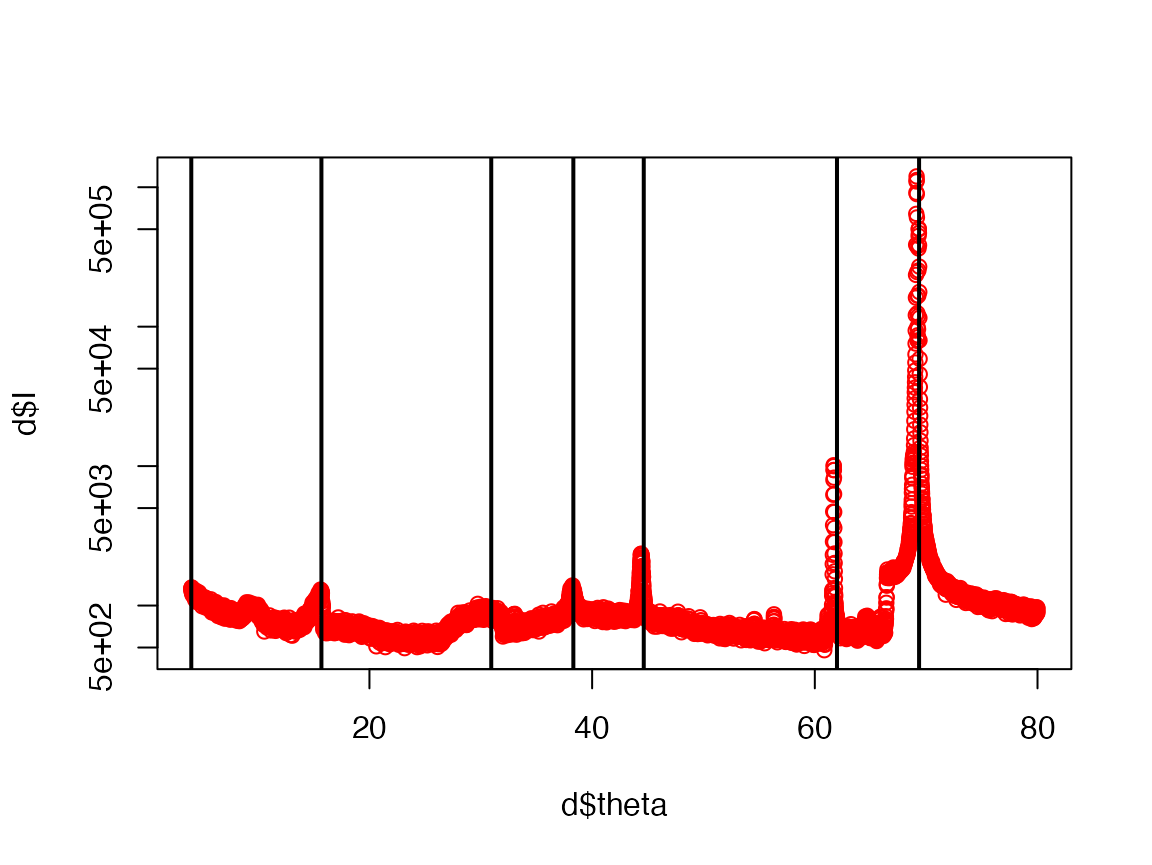
Create subsets of the data with about 10 degrees of data:
filename = xrd.getSampleFiles(fileExt = 'asc')[1]
d = xrd.read.ASC(filename)
peakPos = c()
for(j in 1:7) {
d1 = d %>% filter(theta < j*10+2 & theta > (j-1)*10+2)
p = xrd.peakEstimate(d1$theta, d1$I)
peakPos = c(peakPos, p$th0)
}
plot(d$theta, d$I, log='y', col='red')
abline(v=peakPos,lwd=2)